DDIS Hacker Academy Challenge 2017
The DDIS (danish version of NSA) recruits hackers and has an academy for teaching both offensive and defensive techniques. For their 2017 recruiting campaign they posted a puzzle for us to solve and I must say it is one of the best puzzles I have solved.
Here it is:

On the left, x86 machine code, on the right, base64 encoded something.
The text is not OCR friendly. I tried but there were too many errors that I would have to sort out manually, so I wrote a tool to cut out each character and match them up against a table I built up little by little. If no close match was found the tool would show me the character and I would provide the answer which would go into the table. Little by little the tool should get smarter, but it still took forever.
That was when someone told me to focus on the highlighted characters on the right. Put them together you get MzJoYWNrZXI1NTd6amt6aS5vbmlvbgo and base64 decode them you get 32hacker557zjkzi.onion, a dark web address. If you go there (and if it’s still up) you find two images linking to two text files:


The emu pointed to a transcript of the assembly code on the left and the disk to a transcript of the base64 encoded stuff on the right.
The assembly code
The assembly shows an incomplete implementation of a virtual machine for executing a 32 bit instruction set. It uses three memory regions named DISK, MEM and REGS.
What IS implemented is a BIOS that reads one 512 byte sector from DISK into MEM:
U5_LE:
;Copy 0x200 (512) bytes from DISK to MEM
mov ecx, 0x200 ; Copy 512 bytes
mov edi, MEM ; ...to MEM
mov esi, DISK ; ...from DISK
rep movsb ; Do it!…and a fetch/decode/execute cycle that reads one 32 bit instruction, increments the program counter, zeroes a register (MIPS zero register style), decodes and executes the instruction:
SPIN:
mov edx, REG(63) ; Read 64th entry of REGS table into edx
mov edx, PTR(edx) ; Read MEM+edx into edx
add WORD REG(63), 4 ; Make 64th entry of REGS table point one entry higher
mov WORD REG(0), 0 ; Zero out first entry of REGS table
; The dword retrieved from MEM into edx works like a small language.
; It consists of an opcode and up to three operands like this:
; [AAAA|ABBB|BBBC|CCCC|CDDD|DDD_|____|____]
;
; In the following code this happens:
; * The A's are moved into eax
; * The B's are moved into ebp
; * The C's are moved into esi
; * The D's are moved into edi
;
; The A's are then used to look up an instruction in the OP_TABLE, so those five bits are the opcode
; ebp, edi and esi are operands.
;
; REGS is an array of 64 dwords functioning as registers.
; REGS[63] is the program counter
; REGS[0] is initialized to zero before every execute cycle, works kind of like the MIPS zero register
; Move six bits into ebp (the B's)
mov ebp, edx
shr ebp, 21
and ebp, 77o
; Move six bits into esi (the C's)
mov esi, edx
shr esi, 15
and esi, 77o
; Move six bits into edi (the D's)
mov edi, edx
shr edi, 9
and edi, 77o
; Move top five bits into eax (the A's) and use it to look up an opcode in the OP_TABLE
; Jump to that opcode
mov eax, edx
shr eax, 27
mov eax, [OP_TABLE + eax * 4]
jmp eaxThe last two instructions above isolates the top five bits and use them to look up the instruction in the OP_TABLE and then jumps to the implemenetation. However, only some of the instructions have been implemented, but it turns out they are enough to let us take an educated guess to how the rest should be implemented. A commented version of the implemented instructions folow:
; OP_LOAD_B = Load Byte (one byte)
; OP_LOAD_H = Load Half Word (two bytes)
; OP_LOAD_W = Load Word (four bytes)
; Load Word
; REGS[B] = MEM[REGS[C] + REGS[D]]
OP_LOAD_W:
mov eax, REG(esi)
add eax, REG(edi)
mov eax, PTR(eax)
mov REG(ebp), eax
jmp SPIN
; REGS[B] = REGS[C] * REGS[D]
OP_MUL:
mov eax, REG(esi)
mul DWORD REG(edi)
mov REG(ebp), eax
jmp SPIN
; REGS[B] = I << S
; [AAAA|ABBB|BBBI|IIII|IIII|IIII|IIIS|SSSS]
OP_MOVI:
mov eax, edx
mov ecx, edx
;Isolate 16 bits stating form sixth
shr eax, 5
and eax, 0xffff
;Isolate lower five bits
and ecx, 37o
shl eax, cl ; Left shift the 'I' immediate by 'S' bits
mov REG(ebp), eax ; ..and store them in REGS[B]
jmp SPIN
; if REGS[D] != 0:
; REGS[B] = REGS[C]
OP_CMOV:
mov eax, REG(edi)
test eax, eax
jz .F
mov eax, REG(esi)
mov REG(ebp), eax
.F:
jmp SPIN
; Write to stdout
; putchar(REGS[B])
OP_OUT:
push DWORD REG(ebp)
call putchar
add esp, 4
jmp SPIN
; Read from DISK into MEM the 512 byte block indexed by the B register to the memory address specified by the D register
; memcpy(MEM + REGS[B], DISK + (REGS[C] * 512), 512)
OP_READ:
mov ecx, 0x200
mov esi, REG(esi)
shl esi, 9
lea esi, [DISK + esi]
mov edi, REG(ebp)
lea edi, PTR(edi)
rep movsb
jmp SPINUsing them I implemented the rest as I think they should work into my fe_vm.c.
Running my VM implementation on the base64 decoded data shows that it is in fact bytecode for the vm:
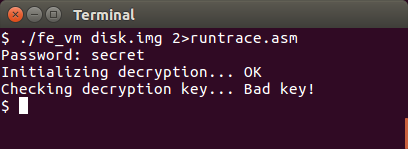
We are asked for a password for decrypting something, but I don’t know the password. I tried different words from the picture of the disk. Also tried different often used passwords without any luck. Disabling my runtrace output made me able to brute force 20-25 passwords per second so I skipped that idea. I guess I have to reverse engineer the bytecode.
Reversing the bytecode
Before getting into the bytecode (here is my commented disassembly) here are some observations about register usage:
r0 = zero register, always contain the value zero
r1 = return value from subrouting calls
r3 = First arg to subroutine calls
r4 = Second arg to subroutine calls
r5 = Third arg to subroutine calls
r59 = Link register, contains return address from subroutine calls
r62 = Stack register
r63 = Program counter, points to next instruction to executeCalling subroutines are done either by ADD or CMOV instructions. ADD is used for unconditional calls and CMOV for conditional ones. Before calling the link register is populated with the address of the instruction following the call and argument registers are populated. For example:
; putstring("OK\n")
030c MOVI r3, 0xaf3 ; Address of "OK\n"
0310 MOVI r57, 0x8 ; Set return address
0314 ADD r59, r63, r57 ; ...more setting return address
0318 MOVI r57, 0x870 ; Address of putstring
031c ADD r63, r57, r0 ; Call putstringI did not reverse engineer the entire thing, only the routines I actually needed which are still most of them. I found a routine that simply wasted time by looping 100.000 times and another routine that called that time wasting routine three times. So, that was the reason the decryption was so slow!
I found out that RC4 was used for decrypting data. RC4 is quite easy to recognize so I stopped reversing after I discovered it. The program checked for a correct password by decrypting a 56 byte data section and matching it against the string "Another one got caught today, it’s all over the papers.". If that was not the result, the "Bad key" message is printed and the program exits. So, to get to the next level we need to do a known plain text attack against RC4.
Breaking the crypto
RC4 has problems. It is a stream cipher, and the output of a good stream cipher is indistinguishable from random, but if I recall correctly the first 100 or so bytes has a bias toward one bits. This is not gonna help me thou so I go for mounting a brute force attack and crossing my fingers. I lifted both the ciphertext and plaintext from the disk image and coded a progam that searches for a usable key: pta.c.
Aaaand it works.
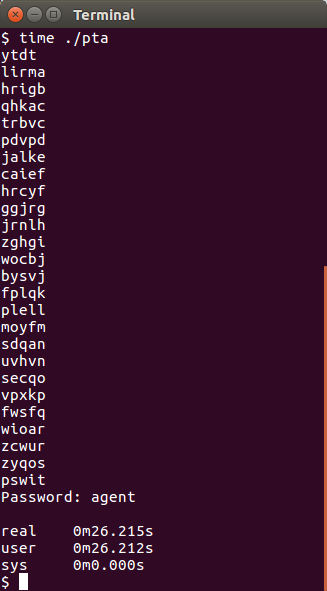
So let’s try with our newfound password.
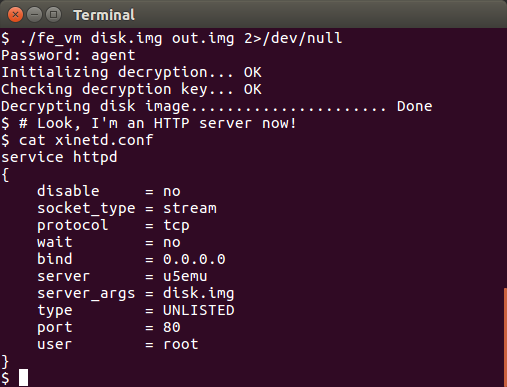
The password is "agent", which is near the top of a dictionary, so we could have solved this by brute forcing the program after all but that would not have been nearly as fun.
The web server
So, the program rewrote itself into a web server and provided us with xinetd configuration for running it. I try that and point my browser towards it but get nothing.
Peeking inside the disk image gets us a couple of probable paths and one of them gives us this:
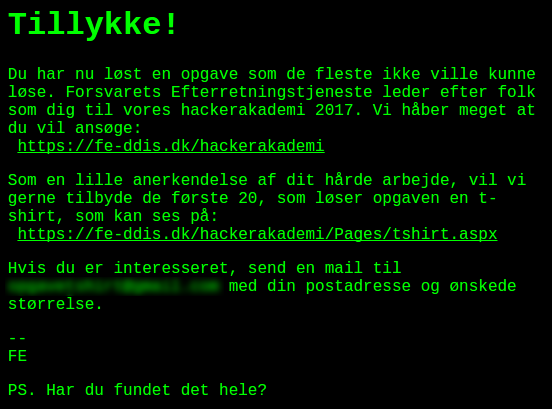
It says something like "Congratulations, you’ve solved a puzzle few people could…yada yada yada…get a free t-shirt".
However it also says "PS: Did you find everything?", so apparently there is more to the challenge. I look into the other URLs I found from peeking into the disk image. A few pictures and a couple of documents. Nothing to see thou and no apparent steganography, so what’s left is looking into the machine code.
Reverse engineering the web server
I start tracing the web server code and produce a disassembly.
The code is pretty easy to read now that I have gained some experience with it and I quickly identify functions like strcpy, strchr, strcmp and others.
The web server reads a line and splits it in request method, request path and http version. Only GET requests are supported.
Then an odd sequence of checks are made (beginning from line 229 in my commented dissembly).
What happens is that a "secret" path is checked for one character at a time and in a random order making it a little harder to follow. I didn’t reverse the entire path because I guessed it eventually.
Following the secret url yields this:
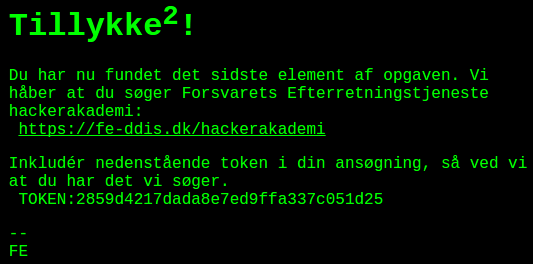
So, apparently I solved it. A pretty well built challenge I must say.